
Real or Not? NLP with Disaster Tweets-CSE 5338 Data Mining Project Phase-02
Published:
Objectives of The Project
The purpose of this project was classification of Disater tweets to identify weather it is Disaster or Not Disaster related. This study has used BERT model which is the Neuaral Network techniques to decode the texts. This study has scored 0.81901 in the kaggle Leaderboard with 969 current position.
Competition Description
Twitter has become an important communication channel in times of emergency. The ubiquitousness of smartphones enables people to announce an emergency they’re observing in real-time. Because of this, more agencies are interested in programatically monitoring Twitter. In this competition, participants are challenged to build a machine learning model that predicts which Tweets are about real disasters and which one’s aren’t.
This dataset was created by the company figure-eight and originally shared on their ‘Data For Everyone’ website here. Tweet source: https://twitter.com/AnyOtherAnnaK/status/629195955506708480
Software
Jupyter Notebook was used in Kaggle online version to perform this whole analysis amd the link of kaggle page is given at the end of this page.
1.0 Import necesssray library for the analysis and model
---
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
import matplotlib.pyplot as plt
import seaborn as sns
from nltk.corpus import stopwords
import re
import string
import pandas_profiling
import random
import string
import tensorflow as tf
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import ModelCheckpoint
import tensorflow_hub as hub
---
1.10 Load 3 different files-train, test and submission
---
train = pd.read_csv("/kaggle/input/nlp-getting-started/train.csv")
test = pd.read_csv("/kaggle/input/nlp-getting-started/test.csv")
sample_submission = pd.read_csv("/kaggle/input/nlp-getting-started/sample_submission.csv")
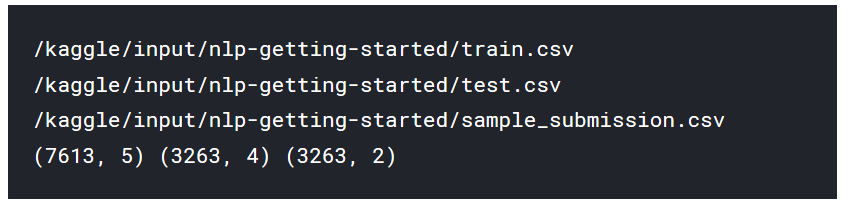
print (train.shape, test.shape, sample_submission.shape)
---  # 1.20 See the data attributes
---
train.head()
test.head()
sample_submission.head()
---


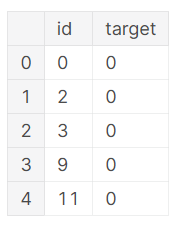
So, it is clear that train set have complete information. Target=1 means disaster and target=0 means non disaster. In test set target column is missing as it should be determind. Then the submission file should be included only Id and determined target for test data set.
2.0 Understanding basic pattern of the data
---
train.duplicated().sum()
train = train.drop_duplicates().reset_index(drop=True)
---
Let see the disaster and non-disaster frequency in traininf set
---
sns.countplot(y=train.target);
---

Lets check with the missing data
---
train.isnull().sum()
test.isnull().sum()
---
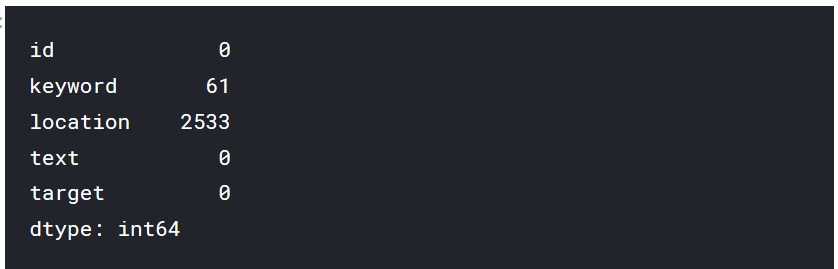
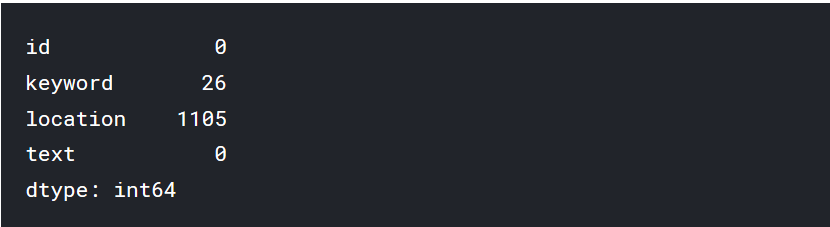
Few kew words and large amount of location data is missing.
--- # lets check the key word similarty in training and test data set
print (train.keyword.nunique(), test.keyword.nunique())
print (set(train.keyword.unique()) - set(test.keyword.unique()))
---

#Both have same number of key words
Most common keywords
---
plt.figure(figsize=(9,6))
sns.countplot(y=train.keyword, order = train.keyword.value_counts().iloc[:15].index)
plt.title('Top 15 keywords')
plt.show()
train.keyword.value_counts().head(10)
---

---
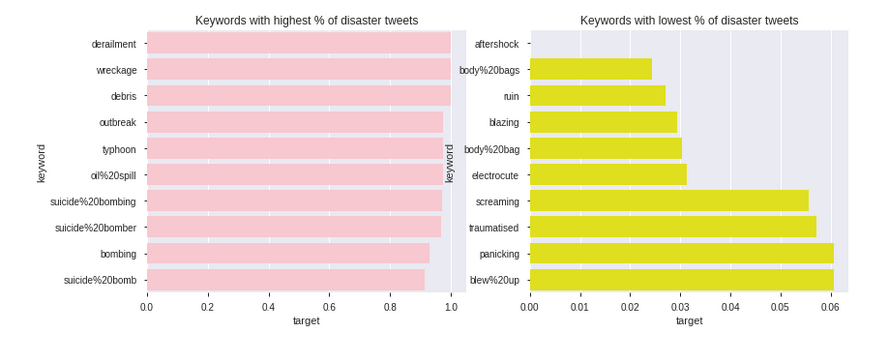
top_d = train.groupby('keyword').mean()['target'].sort_values(ascending=False).head(10)
top_nd = train.groupby('keyword').mean()['target'].sort_values().head(10)
plt.figure(figsize=(13,5))
plt.subplot(121)
sns.barplot(top_d, top_d.index, color='pink')
plt.title('Keywords with highest % of disaster tweets')
plt.subplot(122)
sns.barplot(top_nd, top_nd.index, color='yellow')
plt.title('Keywords with lowest % of disaster tweets')
plt.show()
---
Location identification
---
raw_loc = train.location.value_counts()
top_loc = list(raw_loc[raw_loc>=10].index)
top_only = train[train.location.isin(top_loc)]
top_l = top_only.groupby('location').mean()['target'].sort_values(ascending=False)
plt.figure(figsize=(14,6))
sns.barplot(x=top_l.index, y=top_l)
plt.axhline(np.mean(train.target))
plt.xticks(rotation=80)
plt.show()
---
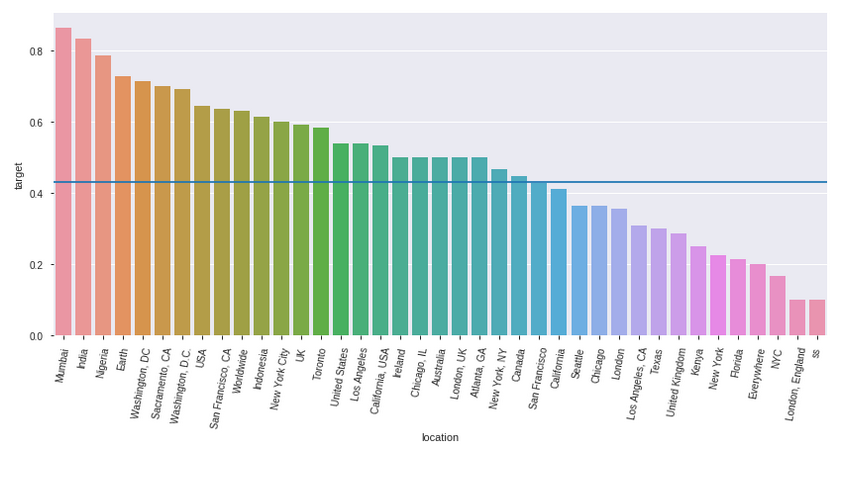 #Uncleared data indicates that Mumbai, India and nigeria are the top three disaster tweets location.
#Uncleared data indicates that Mumbai, India and nigeria are the top three disaster tweets location.
3.0 I am going to use BERT to identify the disaster and non-disaster for test problem set.
BERT stands for Bidirectional Encoder Representations from Transformers. It’s a neural-network based technique for natural language process pretraining. BERT makes use of Transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. In its vanilla form, Transformer includes two separate mechanisms — an encoder that reads the text input and a decoder that produces a prediction for the task. Since BERT’s goal is to generate a language model, only the encoder mechanism is necessary
#Agian import necessary modules — import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) import os for dirname, _, filenames in os.walk(‘/kaggle/working’): for filename in filenames: print(os.path.join(dirname, filename))
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import ModelCheckpoint
import tensorflow_hub as hub ---
Pick the tokenizer
---
!wget --quiet https://raw.githubusercontent.com/tensorflow/models/master/official/nlp/bert/tokenization.py
import tokenization
---
3.10 Helper Functions:
---
def bert_encode(texts, tokenizer, max_len=512):
all_tokens = []
all_masks = []
all_segments = []
for text in texts:
text = tokenizer.tokenize(text)
text = text[:max_len-2]
input_sequence = ["[CLS]"] + text + ["[SEP]"]
pad_len = max_len - len(input_sequence)
tokens = tokenizer.convert_tokens_to_ids(input_sequence)
tokens += [0] * pad_len
pad_masks = [1] * len(input_sequence) + [0] * pad_len
segment_ids = [0] * max_len
all_tokens.append(tokens)
all_masks.append(pad_masks)
all_segments.append(segment_ids)
return np.array(all_tokens), np.array(all_masks), np.array(all_segments)
---
---
def build_model(bert_layer, max_len=512):
input_word_ids = Input(shape=(max_len,), dtype=tf.int32, name="input_word_ids")
input_mask = Input(shape=(max_len,), dtype=tf.int32, name="input_mask")
segment_ids = Input(shape=(max_len,), dtype=tf.int32, name="segment_ids")
_, sequence_output = bert_layer([input_word_ids, input_mask, segment_ids])
clf_output = sequence_output[:, 0, :]
out = Dense(1, activation='sigmoid')(clf_output)
model = Model(inputs=[input_word_ids, input_mask, segment_ids], outputs=out)
model.compile(Adam(lr=2e-6), loss='binary_crossentropy', metrics=['accuracy'])
return model
---
# 3.20 Getting BERT from the Tensorflow Hub
---
%%time
module_url = "https://tfhub.dev/tensorflow/bert_en_uncased_L-24_H-1024_A-16/1"
bert_layer = hub.KerasLayer(module_url, trainable=True)
---

3.30 Taken tokenizer from the bert layer
---
vocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
tokenizer = tokenization.FullTokenizer(vocab_file, do_lower_case)
---
3.40 Now Encoding the text into tokens, masks, and segment flags:
---
train_input = bert_encode(train.text.values, tokenizer, max_len=160)
test_input = bert_encode(test.text.values, tokenizer, max_len=160)
train_labels = train.target.values
---
4.0 Now lets build the model
---
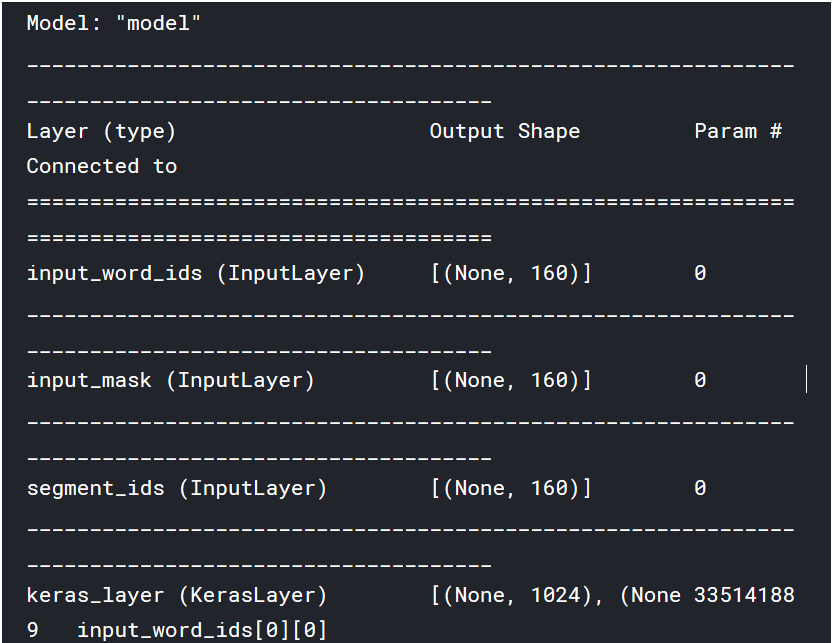
model = build_model(bert_layer, max_len=160)
model.summary()
---
5.0 Train the model
---
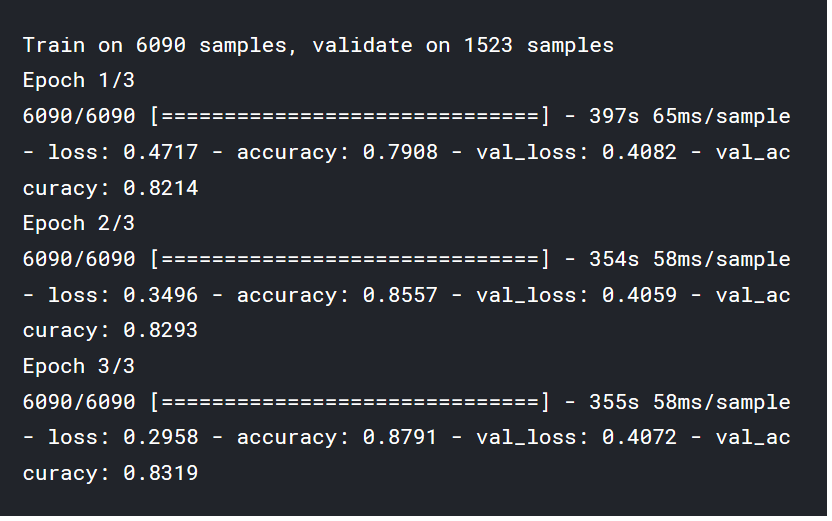
train_history = model.fit(
train_input, train_labels,
validation_split=0.2,
epochs=3,
batch_size=16 )
model.save('model.h5')
--- 
6.0 Predict the target using developed model
---
test_pred = model.predict(test_input)
sample_submission['target'] = test_pred.round().astype(int)
sample_submission.to_csv('sample_submission.csv', index=False)
sample_submission.head()
---
For details, Visit here
6.0 Refernces
https://www.kaggle.com/holfyuen/basic-nlp-on-disaster-tweets
https://www.kaggle.com/nkoprowicz/a-very-simple-fine-tuned-bert-model
https://www.kaggle.com/ratan123/in-depth-guide-to-google-s-bert
https://www.kaggle.com/ratan123/in-depth-guide-to-google-s-bert?fbclid=IwAR3m3AL4vajTMr-IY2kIPPS-eFJJw7Lc9UqJ_nb5cmW5buliW5_qJlfpxgg